Golang Weekly~4 min read·Jun 19, 2026
Go 1.27 Release Candidate 1
#606 — June 19, 2026
Read the Web Version
Go Weekly
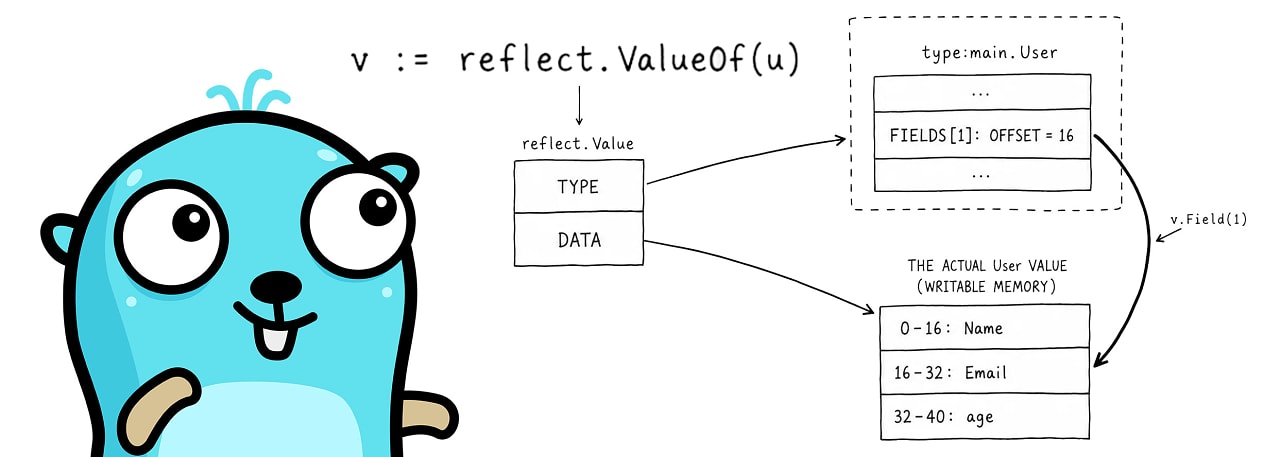
How Go Reflection Really Works — Reflection in a compiled, statically-typed language sounds impossible, but Go can print a struct’s field names, types, and tags at runtime. This look into the Go runtime reveals how: the compiler leaves notes behind for reflect to pick up.
Jesús Espino
Catch Go Bugs Before Your PRs Merge — When AI writes more Go, the code may compile, but a missed error, goroutine leak, or broken handler contract can still ship. Greptile reviews every PR with full repo context, catches real bugs, and lets you run the same review from your terminal.
Greptile sponsor
Go 1.27 Release Candidate 1 Released — “Run it in dev! Run it in prod! File bugs!” says the Go core team. The announcement itself is dry and perfunctory, but the draft release notes have been fleshed out a lot and the final release is expected in August (six months after Go 1.26).
The Go Team
💡 The experimental flag for generic methods has been removed, so you can now get playing with those, as well as the changes to encoding/json.
Finding Leaked Goroutines in Go 1.27 — In April, a new goroutine leak profile was accepted for Go 1.27. Here’s how it uses the GC to find provably-stuck goroutines, plus a comparison to goleak.
Redowan Delowar
▶ Building a pkg.go.dev TUI Explorer with Bubble Tea — A 24-minute video in which Alex demonstrates building a terminal user interface to explore Go modules via the new pkg.go.dev API.
Alex Pliutau
💡 Here's the pkg.go.dev API spec if you want to make something of your own.
How Does struct{} Take Zero Bytes in Go? — You may know that empty structs take up zero bytes, but there are a couple of edge cases that may be new to you.
Budimir Filipović
API for Google Search, Maps, Shopping, Amazon, and More — Unlock your business potential with comprehensive API solutions for Google Search, Maps, Shopping, Amazon, and beyond!
SerpApi sponsor
📄 Dependencies Should Be Fetched Directly from VCS – A Go developer who’s now working with Ruby reflects on Go’s better approach to dependency management. Martin Tournoij
📄 MaxBytes Middleware in Go: The Same Trap, Again Viktor Nikolaiev
🤖 Building Agents in Go Without a Framework Daniel Chalef
🛠 Code & Tools
goja: An ECMAScript/JavaScript Engine in Pure Go — An ECMAScript 5.1 (and ‘most of ES6’) JS implementation for adding scripting functionality to Go apps without pulling in native engines. Related, Sobek is Grafana’s goja fork (originally created to add ESM support more quickly) used in k6.
Dmitry Panov
🤖 gopls's Model Context Protocol (MCP) Server — Go’s official language server includes an experimental MCP server, so AI assistants can query semantic info about code (e.g. symbols, package APIs) rather than guessing from text. It’s a one-liner to add to Claude Code, say.
Official Go Documentation
Kage: Shadow a Website for Offline Viewing — A Go-powered tool that clones a web site and serves it for offline viewing. The novelty vs “Save As” is it handles JS-rendered sites by saving the DOM from a headless browser. GitHub repo.
Duc-Tam Nguyen
📰 Classifieds
⚙️ Middleware, but for AI agents. AgentField composes Claude Code, Codex & Gemini into one harness - Go SDK, 100+ agent recipes, use the language you already ship in. → Star & Deploy.
Echo 5.2 – A security release for the popular web framework.
go-toml 2.4 – The TOML file parser adds TOML 1.1 support.
MongoDB Go Driver 2.7
📢 Go Micro's Agentic Shift…
Go Micro is Becoming a Framework for Agentic Development — The popular distributed microservices framework, now sponsored by Anthropic, is “doubling down on agents”. Instead of composing mere microservices, Go Micro brings a similar mechanic (for models, memory, tools, and guardrails) to build agents instead. v6 just shipped.
Asim Aslam